| |
Despite recent investments in smart grid technologies and alternative energy sources, power failures still pose a significant threat to all industries.
Access to energy sources is critical for all industries. From chemical manufacturin to refineries and warehouses, productivity and business continuity have a vast reliance on an uninterrupted supply of electricity. However, the potential for power failures may also contribute to chemical accident risk on hazardous sites. Unexpected power failures, e.g., triggered by a natural hazard event or equipment failure, can cause a loss of containment of a dangerous substance. When power interruptions and restarts are deliberate, they need to be planned in advance to avoid inadvertently causing release of a dangerous substance.
The Major Accident Hazards Bureau (MAHB) of the European Commission’s Joint Research Centre studied reports of 90 chemical incidents from multiple industrial sectors to understand how and why power supply failures cause chemical accidents and identify practices to prevent them and mitigate their effects. The findings were analyzed to provide lessons learned to support risk assessment and risk management decisions on hazardous sites.
Impacts of power failure-related accidents on hazardous sites
The accident reports indicated that power failures on hazardous sites have resulted in 21 fatalities and over 9500 injuries worldwide since 1981, as well as significant property damage and production loss from resulting fires and explosions. The impacts from one power failure can be devastating. The most catastrophic event in the study occurred in Sakai (Osaka), Japan in 1982, that killed 6 people, injured 9,080 others (of which 8,876 were offsite) and destroyed 1,788 buildings. As another example, a power failure-related accident that occurred in Puertollano, Spain, caused 9 fatalities, 10 injuries and around €54 million in property damage with over 25% of the plant destroyed. It is notable that many incidents had significant offsite impacts, particularly from toxic releases. More than half of the cases (48 cases or 53%) involved a toxic release and of these, evacuation and shelter in place were ordered in 12 cases (13%). As a case in point, a power failure at a refinery in Antwerp, Belgium in 2008 caused the release of hydrogen sulfide. The toxic cloud traveled about 50 kilometers over Belgium and parts of the Netherlands, affecting several hundreds of people and causing 57 persons to seek medical care. Nonetheless, only a small number of cases (8%) had significant impacts on the environment, affecting mostly aquatic life. In one case, effluent from a sugar refinery was released following a power failure in 2012 polluting the Oeuf stream of Pithiviers-le-Vieil in France, causing a massive fish kill.
Power failures characteristics
Our study showed that there are a number of commonalities across power failures events on hazardous sites. In particular, power failures:
- Are often unpredictable (i.e., weather conditions or pubic supply failures).
| |
 Figure 2. Impact of power failures Figure 2. Impact of power failures
|
- Can affect multiple units and equipment (common mode failure).
- Can affect most industries with one or more unintended consequences.
- May destabilize units and compromise process safety, sometimes in ways that may not have been foreseen.
- Can have delayed impacts if process consequences are not recognised and controlled.
- Can have worse impacts when poor process safety practices have already weakened operator resilience.
- Can have significant impact on facilities even without loss of containment, such as loss of product from flaring, loss of revenue from plant shutdowns, and damage to equipment and buildings.
Scenarios triggered by a primary failure in the external power supply
Of the accidents studied, 34 incidents (or 38%) were initiated due to a loss of offsite power supply. Power failures or outages can be categorized into two distinct phenomena; blackouts and brownouts. Blackouts refer to a complete loss of power, whereas brownouts occur when facilities experience power disturbances, such as voltage fluctuations (partial outage), that can cause damage to electronics or equipment. Power suppliers may impose brownouts for load reduction in an emergency or in order to avoid a complete blackout. Each electrical apparatus may react in a different way to such voltage fluctuations, and some may be severely affected while others are not affected at all. Across the incidents studied, in 20 cases (22%) the public power supply failed while extreme weather conditions were reported as contributing factors leading to cascading technical failures and consequently power outages in 14 cases (16%). Electrical substations, either internal or external of a facility, as well as the power grid experienced failures following mostly thunderstorms (12 cases) or severe snowfall.
Chemical accidents that follow power failures are a combination of two accident sequences. The first accident sequence is the power failure itself, sometimes also followed by the failure of backup systems. The second accident sequence begins with the loss of containment triggered by the power failure. The facility’s response to the power failure will determine to a great extent the outcome of the second accident sequence. A controlled response may entail triggering shutdown procedures or addressing the power failure by switching the facility’s suppply to redundant power sources. Safe recovery from a power failure avoids a sequence of events leading to loss of containment and potentially a serious or catastrophic chemical accident.
Typically, power failure is followed by variation of one of the following circumstances:
- With the support of an uninterrupted power supply (UPS), connection to a backup power supply and/or controlled shutdown of the site.
- With the support of a UPS system, the site continues functioning but the backup power supply fails, and the site goes into a controlled emergency shutdown.
- Without a backup power supply, some processes, or the entire site, may undergo an uncontrolled emergency shutdown.
- Following the planned or unplanned shutdown, the site or specific processes will start up again. This is called recovery.
There are always high risks even in controlled shutdowns and startups. Uncontrolled emergency shutdowns entail even higher risks, but plants can still plan measures that can reduce impacts from these types of events.
Causes of primary power failure
The JRC study also found that the loss of primary power failure was mostly attributed to failures of onsite electrical equipment or electrical components (35 cases or 39%) as shown in Figure 2. Most electrical equipment failures were related to:
| |
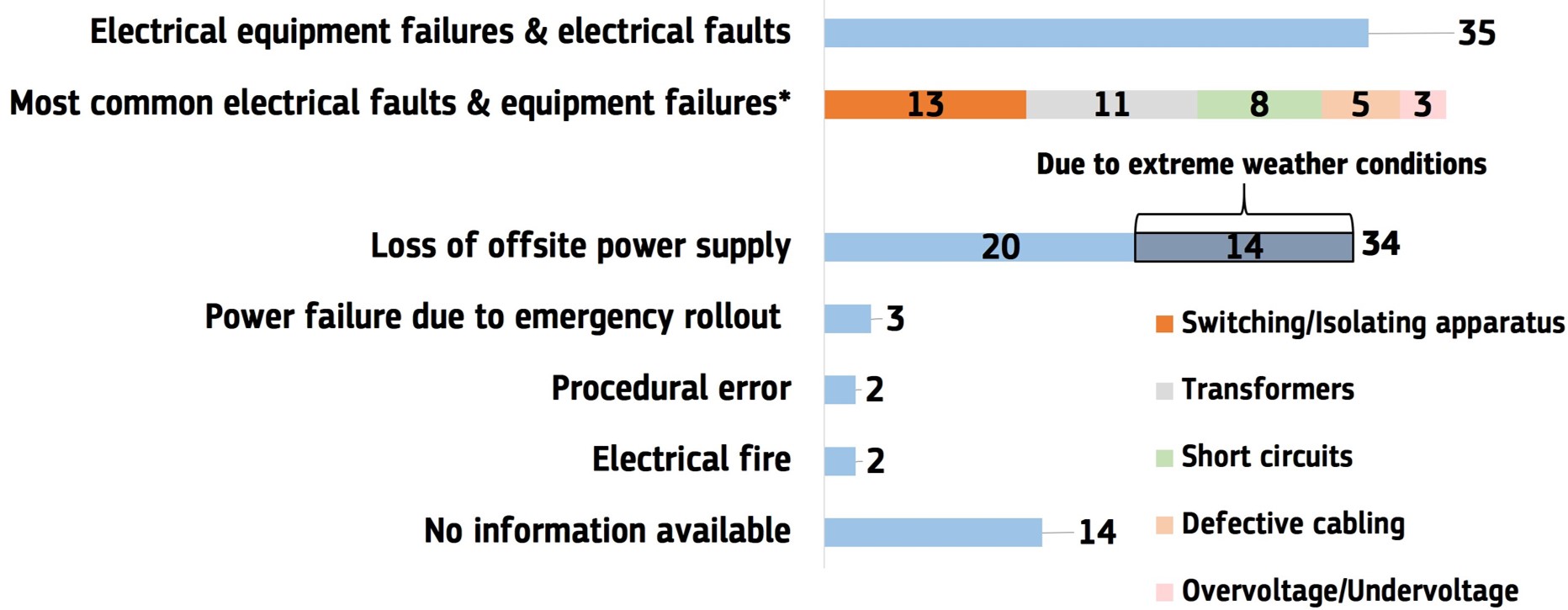
Figure 3. Causes of primary power supply failure (N=90)
(*Some cases have more than one failure)
|
- Electrical switching and isolating apparatus, such as circuit switches and circuit breakers that failed to open or close on demand (13 cases).
- Transformers failing (11 cases).
- Short circuits (e.g., due to faulty equipment, loose wire connection), resulting in flow of abnormally high currents through equipment or transmission lines (8 cases).
- Defective cabling (due to improper installation or insufficient maintenance) (5 cases).
- Undervoltage (reduction in the system voltage) or overvoltage (swell in voltage levels), significantly affecting the “power quality” causing disruption of power to and from equipment (3 cases)
Failures in the redundant power supply
In 33 cases (37%), redundant systems were in place but failed to operate successfully, leading to unsuccessful recovery from the primary power failure. The majority of failures related to the backup power systems were found in generators. Typical scenarios included:
- Failure of onsite generators (whether steam or fossil fueled) (19 cases).
- Failure in the switching operation between the primary power supply and the available backup systems (7 cases).
- Failure of the UPS systems (4 cases).
- Other common faults, such as short circuiits (4 cases) and overvoltage or undervoltage (2 cases) led to loss of the redundant power supply.
Impact of power failure on facilities
Electricity is used for a number of different purposes in process plants. Power failures will often affect facilities acting as common mode failures disturbing multiple process aspects simultaneously. Reactor cooling and agitation, for example, were both lost in ten cases (11%). In two of these cases, firefighting and alarms were also lost following a power failure. Power failures can, therefore, affect the smooth function of numerous plant operations, including:
- Operation of machinery, heating, cooling, presure safety valves (PSVs) and instrumentation.
- The basic process control system (BPCS), monitoring devices and alarm, and control mechanisms such as valves, pumps or agitators.
- Safety critical instruments and emergency equipment
Moreover, digital control circuits may experience disruptions. During an undervoltage scenario, control signals may fall below the threshold at which logic controllers can reliably detect the represented equipment state (valve open or closed, motor pump open/closed or flowing downstream/upstream). Upon recovery the signal may differ from the actual position of the equipment, leading to blockades or flow contradictory to process intent.
Loss of power can result in a cascade of failure in a facility. Such cases have been observed where loss of power rendered boilers inoperable, consequently affecting the steam production.
|
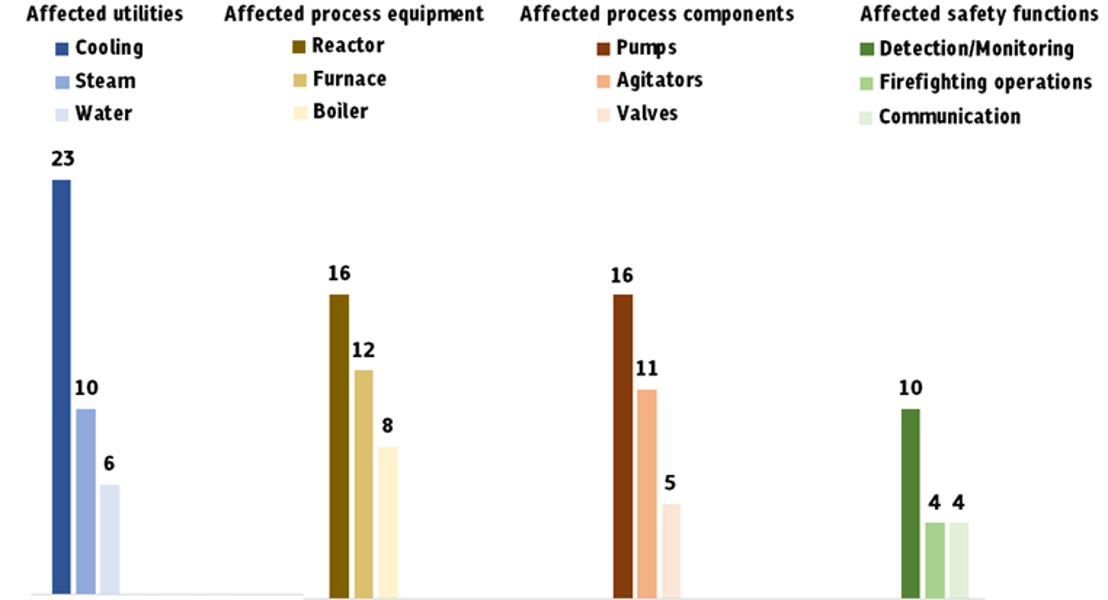 Figure 4. Process utilities, equipment, components and safety functions affected by the power failure (N=90) Figure 4. Process utilities, equipment, components and safety functions affected by the power failure (N=90)
|
|
Cooling was the utility most affected (23 cases or 26%) among cases in which power loss adversely affected one or more utilities, as shown in Figure 3. Loss of electrical driven pumps will result in loss of cooling since heat exchange depends primarily on continued pump operation, both for the process fluid and for the cooling water. A sudden current fluctuation may trigger the pump’s motor overcurrent protection and stop the pump creating blocked routes. Cases where pumps tripped in an open position following a power outage, allowing process material flow unexpectedly have also been noticed. Other cooling equipment affected can include fans of air-cooled heat exchangers and fans on ovens or furnaces intended to avoid the formation of a flammable or explosive atmosphere.
Reactors were found to be the most vulnerable equipment, since cooling and/or agitation over reaction mixtures were lost in 16 cases (18%) leading to potential runaway scenarios. In 12 cases (13%) furnaces, necessary for processes such as steam cracking, failed following a power outage whereas boilers, one of the most fundamental systems of a refinery or chemical processing plant responsible for steam production were lost in eight cases (9%). Other equipment affected by power loss included pumps, circulating process substances, firefighting water or cooling mediums (16 cases or 18%) and agitators for reaction mixtures (11 cases or 12%).
Mitigation and emergency response equipment lost functionality in a number of cases. Safety functions, such as gas detectors, as well as monitoring systems (e.g., level sensors) were affected by power failure in 10 cases (11%). In four cases firefighting operations, water hydrants or sprinklers, were deemed inoperable following the power failure, while in four more communication internally or externally to the facility was lost.
|
|
